
넘블/딥다이브 [방문자 수 트래킹 서비스 구축하기] 프로젝트 진행 중 이슈에 대한 트러블 슈팅과정입니다.
이슈 전 프로젝트 상황 설명
[Spring Boot + JPA + MySQL] 기반 프로젝트이다.
방문자 수 트래킹을 기록하기 위한 테이블 구성은 아래와 같이 구성하였고 일자별 특정 URL에 대한 방문 조회수를 기록하는 형태이다.
@Entity
public class UrlCounter {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, length = 200)
private String url;
@Column(nullable = false)
private LocalDate date;
@Column(nullable = false)
private int count;
}이슈
조회수를 증가시키는 비즈니스 로직은 특정 URL의 오늘일자를 데이터를 조회하여 없으면 Insert, 있으면 Update 하는 형태로 구성하였다.
JPA 기반 프로젝트이므로 객체를 활용하기 위해 Entity의 조회수 증가 메서드를 생성하여 호출하여 사용하였다.
// Entity
@Entity
public class UrlCounter {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, length = 200)
private String url;
@Column(nullable = false)
private LocalDate date;
@Column(nullable = false)
private int count;
public void increase(int count){
this.count += count;
}
}
// Service
@Service
@RequiredArgsConstructor
public class UrlCounterServiceImpl implements UrlCounterService {
[ ... ]
@Override
@Transactional
public UrlCounterResponse increaseCounter(String url) {
UrlCounter counter = urlCounterRepository.findByUrlAndDate(url, TODAY)
.orElse(new UrlCounter(url, TODAY));
LOGGER.info("[increaseCounter before] url : {}, count : {}", counter.getUrl(),
counter.getCount());
if(counter.getId() != null){
counter.increase(1);
}
UrlCounter result = urlCounterRepository.saveAndFlush(counter);
LOGGER.info("[increaseCounter insert] url : {}, count : {}", result.getUrl(),
result.getCount());
return new UrlCounterResponse(result);
}
[ ... ]
}기본적으로 아무런 처리를 안 하고 멀티스레드 테스트를 진행하면 동시성 이슈가 발생하게 된다.
@SpringBootTest
class UrlCounterServiceConcurrencyTest {
@Autowired
private UrlCounterRepository urlCounterRepository;
@Autowired
private UrlCounterService urlCounterService;
@BeforeEach
public void insert(){
UrlCounter urlCounter = new UrlCounter("https://jh7722.test.com/",LocalDate.now());
urlCounterRepository.saveAndFlush(urlCounter);
}
@AfterEach
public void delete() {
urlCounterRepository.deleteAll();
}
@Test
@DisplayName("동시에 50명이 특정 URL을 조회")
void increaseCounterConcurrency() throws InterruptedException {
AtomicInteger successCount = new AtomicInteger();
int threadCount = 50;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
urlCounterService.increaseCounter(
"https://jh7722.test.com/");
successCount.getAndIncrement();
} catch (ObjectOptimisticLockingFailureException oe) {
System.out.println("충돌감지");
} catch (Exception e) {
System.out.println(e.getMessage());
} finally {
latch.countDown();
}
});
}
latch.await();
Long urlCounter = urlCounterRepository.findUrlCounter("https://jh7722.test.com/",
LocalDate.now());
assertThat(successCount.get()).isEqualTo(threadCount);
// 1+50
assertThat(urlCounter).isEqualTo(51);
}
}ExcutorService는 Thread를 이용해 비동기로 다수의 작업을 테스트하기 위해 사용하였고 테스트를 진행시켜 보면 초기 Insert값을 포함한 50번의 동작을 하므로 조회카운터가 51이 나와야 한다.
하지만 테스트 결과를 보면 정상적으로 나오지 않는다는 것을 알 수 있다.
이런 결과가 나오는 이유는 한 자원에 대한 Transaction이 동시 접근하면 경쟁 상태(Race Condition)가 발생되기 때문이다.
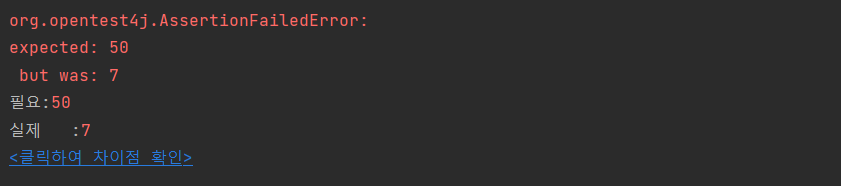
이슈해결을 위한 시도
레이스컨디션을 해결하기 위해선 데이터의 한 개의 스레드만 접근 가능하도록 하면 된다.
synchronized 이용한 방법
1차적으로 자바에서 지원하는 synchronized 이용하였다. 자바에서 해당 키워드를 이용하면 한 개의 스레드만 접근 가능하도록 할 수 있다.
주의할 점은 @Transactional 어노테이션을 사용하면 문제가 발생된다. 둘이 같이 사용하게 된다면 한 스레드가 끝나기 전에 다른 스레드가 발동될 수 있다고 한다.
@Override
//@Transactional
public synchronized UrlCounterResponse increaseCounter(String url) {
UrlCounter counter = urlCounterRepository.findByUrlAndDate(url, TODAY)
.orElse(new UrlCounter(url, TODAY));
LOGGER.info("[increaseCounter before] url : {}, count : {}", counter.getUrl(),
counter.getCount());
if(counter.getId() != null){
counter.increase(1);
}
UrlCounter result = urlCounterRepository.saveAndFlush(counter);
LOGGER.info("[increaseCounter insert] url : {}, count : {}", result.getUrl(),
result.getCount());
return new UrlCounterResponse(result);
}테스트가 성공되는 것을 알 수 있다.

하지만 해당 방법에는 이슈가 존재한다. 해당 방식은 하나의 프로세서 안에서만 동작을 보장한다.
즉, 분산처리 환경에서 사용할 수 없다는 것이다. 현재 내 프로젝트에서는 큰 문제가 발생되지 않지만 요즘에는 대부분 한 서버만 두고 서비스를 론칭하지 않기 때문에 사실상 이 방법으로 동시성 이슈를 해결하기엔 어렵다.
Pessimistic Lock을 이용한 방법
Pessimistic Lock은 실제로 데이터에 락을 걸어서 정합성을 맞추는 방법이다. Exclusive Lock을 걸게 되면 다른 트랜잭션에서는 락이 해체되기 전에 락을 걸고 데이터를 가져갈 수 없게 된다.
Pessimistic Lock을 활용하기 위해 JPA의 @Lock 어노테이션을 활용하였다. 현재 [Select ~ Count+1 ~ Insert/Update] 구조이기 때문에 Select 쪽에 Lock을 걸어 진행하였다.
@Repository
public interface UrlCounterRepository extends JpaRepository<UrlCounter, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select u from UrlCounter u where u.url = :url and u.date = :date")
Optional<UrlCounter> findByUrlAndDate(@Param("url") String url, @Param("date") LocalDate date);
[ ... ]
}@Lock은 @Transactional 안에서 동작하므로 Service의 비즈니스 로직에 선언하여 사용하였다.
@Override
@Transactional
public UrlCounterResponse increaseCounter(String url) {
// 위와 동일
[ ... ]
}
테스트 진행해보면 동작이 정상적으로 되지 않는다. 특별한 예외오류는 발생되지 않았고 쿼리를 분석해 보면 동일값 업데이트가 지속적으로 이뤄진 것을 확인할 수 있었다.
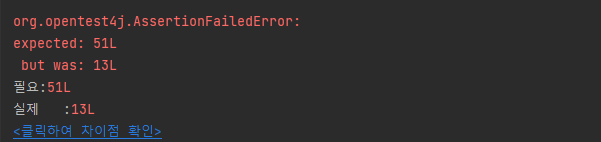
여전히 조회 후 update 가 끝나고 다른 Transaction이 발생돼야 하는데 그런 동작 방식이 이루어지지 않는 것 같다. (이 부분은 더 공부가 필요할 듯)
Update 쿼리를 변경하여 진행
현재 구조 JPA를 활용하기에 객체의 메세지를 던져 카운터를 증가시키는 방식으로 진행하였다. 그럼 구조적으로 'update url_counter set count=`증가된 값` where url=url and date = date' 형태가 되게 된다. 구조적으로 보면 문제가 발생되지 않지만 멀티 요청 환경에서는 '증가된 값'이 요청 순서와 다르게 될 수 있는다는 리스크를 갖게 된다.
사실 그런 것을 처리하기 위해 Lock을 활용한 것인데 정상적으로 동작하지 않아 위 비즈니스 로직을 변경하기로 하였다. 기존 Sava()를 활용한 방식에서 쿼리를 직접 선언하여 'update url_counter set count = count +1 where url=url and date = date' 방식으로 변경하여 진행하였다.
@Modifying(clearAutomatically = true, flushAutomatically = true)
@Query(value = "update UrlCounter u set u.count = u.count + 1 where u.id = :urlCountId")
void increaseUrlCount(Long urlCountId);@Override
@Transactional
public UrlCounterResponse increaseCounter(String url) {
UrlCounter counter = urlCounterRepository.findByUrlAndDate(url, TODAY)
.orElse(new UrlCounter(url, TODAY));
LOGGER.info("[increaseCounter before] url : {}, count : {}", counter.getUrl(),
counter.getCount());
// 이전 코드
/*if(counter.getId() != null){
counter.increase(1);
}
UrlCounter result = urlCounterRepository.save(counter);
LOGGER.info("[increaseCounter insert] url : {}, count : {}", result.getUrl(),
result.getCount());
return new UrlCounterResponse(result);*/
// 변경 코드
if(counter.getId() == null){
UrlCounter result = urlCounterRepository.saveAndFlush(counter);
LOGGER.info("[increaseCounter insert] url : {}, count : {}", result.getUrl(),
result.getCount());
return new UrlCounterResponse(result);
}
urlCounterRepository.increaseUrlCount(counter.getId());
UrlCounter result = urlCounterRepository.findById(counter.getId()).get();
LOGGER.info("[increaseCounter update] url : {}, count : {}", result.getUrl(),
result.getCount());
return new UrlCounterResponse(result);
}서비스 로직도 변경하고 테스트를 진행해보자.

테스트가 정상적으로 동작하였다.
최종 이슈 해결 방법
이슈가 해결된 줄 알았지만 여전히 고려해야 할 부분이 존재하였다. 처음에 이야기했듯이 해당 서비스 로직은 Insert와 Update가 동시에 발생할 수 있는 코드이다.
하지만 테스트 시에는 Insert 부분을 @BeforeEach로 미리 선언하고 진행하였기에 사실상 Update 구문 하나에 대한 테스트 진행이었다. 실제로 해당 부분을 제외하고 테스트하면 여전히 테스트 통과를 하지 못한다.
@BeforeEach
public void insert(){
UrlCounter urlCounter = new UrlCounter("https://jh7722.test.com/",LocalDate.now());
urlCounterRepository.saveAndFlush(urlCounter);
}
일차적으로 문제는 다중 Insert가 발생에 대한 예외를 하지 않았다는 점으로 Unique Key를 설정하여 일단 중복 Insert가 발생되는 것을 막았다.
@Entity
@Table(name = "url_counter",
uniqueConstraints = @UniqueConstraint(columnNames = {"url", "date"}),
indexes = @Index(name = "idx__url__date", columnList = "url, date", unique = true))
public class UrlCounter {
[ ... ]
}데이터 중복은 막았지만 여전히 Insert 구문이 중복으로 발생되어 해당 이슈가 발생되었다.

이런 중복이 발생되었을 때 다시 Retry해주는 방법을 필요하였고 개발자가 직접 이슈에 대한 Retry 로직을 만들어줘야 하는 Optimistic Lock 활용하게 되었다.
Optimistic Lock 설정 과정
마찬가지로 @Lock 어노테이션을 활용하면 쉽게 설정할 수 있다.
@Lock(LockModeType.OPTIMISTIC)
@Query("select u from UrlCounter u where u.url = :url and u.date = :date")
Optional<UrlCounter> findByUrlAndDate(@Param("url") String url, @Param("date") LocalDate date);Optimistic Lock은 버전을 활용하기 때문에 Entity에 버전 칼럼을 추가해야한다.
@Entity
@Table(name = "url_counter",
uniqueConstraints = @UniqueConstraint(columnNames = {"url", "date"}),
indexes = @Index(name = "idx__url__date", columnList = "url, date", unique = true))
public class UrlCounter {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, length = 200)
private String url;
@Column(nullable = false)
private LocalDate date;
@Column(nullable = false)
private int count;
@Version
private int version;
[ ... ]
}마지막으로 예외 발생 시 재동작을 위한 로직을 구성해주면 된다.
@Component
public class OptimisticLockStockFacade {
private UrlCounterService urlCounterService;
public OptimisticLockStockFacade(UrlCounterService urlCounterService) {
this.urlCounterService = urlCounterService;
}
public UrlCounterResponse increaseCounter(String url) throws InterruptedException {
while (true) {
try {
UrlCounterResponse urlCounterResponse = urlCounterService.increaseCounter(url);
return urlCounterResponse;
} catch (Exception e) {
Thread.sleep(50);
}
}
}
}위에 테스트 코드에서 @BeforeEach를 주석처리하고 위에서 생성한 로직으로 변경테스트를 진행한다.
@Autowired
// private UrlCounterService urlCounterService;
private OptimisticLockStockFacade urlCounterService;이렇게 구성한 후 Insert와 Update를 동시 테스트 하면 정상적으로 진행된 것을 확인할 수 있다.

정리를 마치며
여전히 JPA 기초 지식이 부족하고 추가적으로 공부할 필요를 느끼며 RDBMS에서 트랜잭션과 락이 어떤 방식을 동작하는지도 정확히 몰라 이슈를 완벽히 해결했다고 생각되지 않는다.
# @Transaction 사용 시 정확한 동작 원리 정리
# @Lock 조건에 따른 RDBMS 동작 원리 정리
# JPA에서 객체를 이용한 save() 방식과 네이티브 쿼리 이용 방식의 차이
# RDBMS 말고 Redis 로 동시성 처리해보기
Reference
[인프런 - 재고시스템으로 알아보는 동시성이슈 해결방안]
https://hojun-dev.tistory.com/entry/JAVA-JPA-다중-서버-환경-DB-동시성-문제-해결하기