
01. 데이터 모델의 이해
(1) 모델링이란?
건축 모델링, 석고상 모델링, 3D 소프트웨어 모델링 등 모델링은 다양한 분야에 활용된다. 다양한 분야에서 활용되는 모델링의 공통 분모를 찾아보면 '설계', '디자인', '형상' 등의 단어들을 추출해낼 수 있다. 데이터베이스에서의 모델링도 마찬가지로 이런 단어들을 접목해보면 쉽게 이해할 수 있다.
데이터베이스에서의 모델링은 '현실 세계를 단순화하여 표현하는 기법'이다. 예를 들어보자 배달 앱을 이용해 음식을 주문한다고 가정하였을 때 이것을 도식화 하면 나(고객), 음식(상품), 그리고 주문하는 행위로 나눌 수 있다.
단순한 예시이지만 내가 현실세계에서 하는 행위가 모델이 만들어짐에 따라 모델링되는 것을 확인 할 수 있다. 모델은 이처럼 현실 세계에서 일어날 수 있는 다양한 현상에 대해서 일정한 표기법에 의해 표현해 놓은 모형을 의미하며, 모델링은 이런 모델을 만들어가는 일이라고 할 수 있다.
모델링이 갖춰야 할 조건
- 현실세계를 반영해야 한다.
- 단순화하여 표현해야 한다.
- 관리하고자 하는 데이터를 모델로 설계한다.
(2) 모델링의 특징
- 추상화(Abstraction)
현실 세계를 일정한 형식으로 표현한 것이다. 즉, 아이디어나 개념을 간략하게 표현한 것이다. - 단순화(Simplification)
복잡한 현실 세계를 정해진 표기법으로 단순하고 쉽게 표현하다는 것을 의미한다. - 명확화(Clarity)
불분명함을 제거하고 명확하게 해석할 수 있도록 기술한다는 의미이다.
데이터베이스 모델링은 결론적으로 '현실세계를 추상화, 단순화, 명확화하기 위해 일정한 표기법에 위해 표현되는 기법'이다.
(3) 모델링의 세 가지 관점
- 데이터 관점(What, Data)
데이터 위주의 모델링이라고 할 수 있다. 어떤 데이터들이 업무와 얽혀있는지, 그리그 그 데이터간에는 어떤 관계가 있는지에 대해서 모델링하는 방법이다. - 프로세스 관점(How, Process)
프로세스 위주의 모델링이라고 할 수 있다. 이 업무가 실제로 처리하고 있는 일은 무엇인지 또는 앞으로 처리해야 하는 일은 무엇인지를 모델링하는 방법이다. - 데이터와 프로세스의 상관 관점(Data vs. Process, interaction)
데이터와 프로세스의 관계를 위주로 한 모델링이라고 할 수 있다. 프로세서의 흐름에 따라 데이터가 어떤 영향을 받는지를 모델링하는 방법이다.
(4) 모델링의 세 가지 단계
- 개념적 데이터 모델링(Conceptual Data Modeling)
전사적 데이터 모델링 수행 시 행해지며 추상화 레벨이 가장 높은 모델링이다. 이 단계에서는 업무 중심적이고 포괄적인 수준의 모델링이 진행된다. - 논리적 데이터 모델링(Logical Data Modeling)
재사용성이 가장 높은 모델링으로 데이터베이스 모델에 대한 Key, 속성, 관계 등을 모두 표현하는 단계이다. - 물리적 데이터 모델링(Physical Data Modeling)
실제 데이터베이스로 구현할 수 있도록 성능이나 가용성 등의 물리적인 성격을 고려하여 모델을 표현하는 단계이다.
(5) 데이터의 독립성

3단계 스키마 구조
- 외부 스키마
사용자의 관점 : Multiple User`s View 단계로 각각의 사용자가 보는 데이터베이스의 스키마를 정의한다.(사용자 관점으로 접근하는 특성에 따른 스키마 구성) - 개념 스키마
통합된 관점 : Community View of DB 단계로 모든 사용자가 보는 데이터베이스의 스키마를 통합하여 전체 데이터베이스를 나타내는 것이다. 데이터베이스에 저장되는 데이터들을 표현하고 데이터들 간의 관계를 나타낸다. (통합 관점) - 내부 스키마
물리적인 관점 : Physical Representation 단계로 물리적인 저장 구조를 나타낸다. 실질적인 데이터의 저장 구조나 칼럼 정의, 인덱스 등을 포함한다.
3단계 스키마 구조가 보장하는 독립성
ANSI-SPARC 아키텍처에서 이렇게 스키마를 3단계 구조르 나누는 이유는 데이터베이스에 대한 사용자들의 관점과 데이터베이스가 실제로 표현되는 물리적인 방식을 분리하여 독립성을 보장하기 위한 것이다.
- 논리적 독립성 : 개념 스키마가 변경되어도 외부 스키마는 영향받지 않는다. 논리적 구조가 변경되어도 응용 프로그램에 영향이 없다. (사용자 특성에 맞는 변경이 가능하며 통합 구조 변경이 가능하다.)
- 물리적 독립성 : 내부 스키마가 변경되어도 외부/개념 스키마는 영향받지 않는다. 저장정치의 구조변경은 응용프로그래밍과 개념 스키마에 영향을 주지 않는다. (물리적 구조 영향 없이 개념구조 변경가능, 개념구조 영향 없이 물리적인 구조 변경가능)
(6) ERD
시스템에 어떤 엔터티들이 존재하며 그들 간에 어떤 관계가 있는지를 나타내는 다이어그램이다.
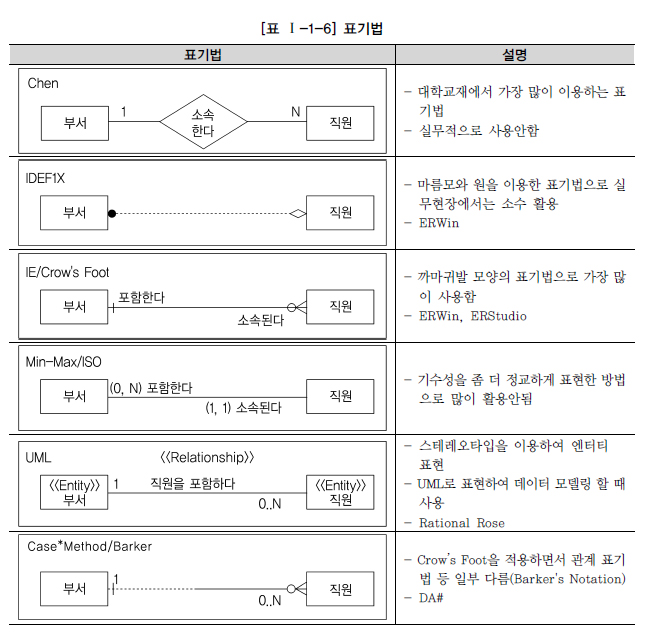
IE/Crow`s Foot 표기법

ERD 작성 순서
- 엔티티를 도출하고 그린다.
- 엔티티를 적절하게 배치한다.
- 엔티티 간의 관계를 설정한다.
- 관계명을 기입한다.
- 관계의 참여도를 기입한다.
- 관계의 필수/선택 여부를 기입한다.
※ 데이터 모델링의 유의점
- 중복(Duplication)
데이터 모델은 같은 데이터를 사용하는 사람, 시간, 장소를 파악하는데 도움을 준다.
이러한 지식응용은 데이터베이스가 여러 장소에 같은 정보를 저장하는 잘못을 하지 않도록 한다.- 비유연성(Inflexibility)
데이터의 정의를 데이터의 사용 프로세스와 분리함으로써
데이터 모델링은 데이터 혹은 프로세스츼 작은 변화가 애플리케이션과 데이터베이스에 중대한 변화를
일으킬 수 있는 가능성을 줄인다.- 비일관성(Inconsistency)
데이터 중복이 없더라도 비일관성은 발생한다.
데이터 모델링을 할 때 데이터와 데이터간 상호 연관 관계에 대한 명확한 정의는 이러한 위험을 사전에 예방한다.
'DB' 카테고리의 다른 글
| [DB/SQLD] 데이터 모델링의 이해 (2) (0) | 2023.11.13 |
|---|---|
| [DB] 커넥션 풀의 이해 (0) | 2023.11.02 |